Eine Website besteht aus vielen Einzelseiten. Je älter sie ist und je umfangreicher, umso komplizierter wird es, Zahl und Struktur aller Seiten im Auge zu behalten und Probleme darin zu finden. Technisch gesehen, erzeugt sogar jeder verwendete URL-Parameter in Kombination mit seinem Wert eine neue Seite. Gerade, wenn es dann darum geht, Stolpersteine aufzudecken und Optimierungen durchzuführen, hilft Handarbeit in Form von manuellen Analysen vielfach nicht weiter.
Gleichzeitig verlangt eine verstärkte Tendenz hin zu mobil verwendbaren Websites eine Beachtung aller möglichen Fallstricke, die die Ladezeiten von Seiten negativ beeinflussen. Nachdem nun die Telekom eine Datendrosselung ihrer DSL-Anschlüsse eingeführt hat, ist selbst die großflächige Verfügbarkeit schneller Internetverbindungen keine Ausrede mehr für langsame Websites – ganz abgesehen davon, dass Suchmaschinen wie Google ganz offiziell schnelle Websites bevorzugen.
Fragen zu diesem Thema laufen mir im SEO-Alltag deshalb regelmäßig über den Weg. Schließlich ist die technische Optimierung der eigenen Website einer der drei Grundpfeiler für die Optimierung – und vor allem etwas, was der Websitebetreiber i.d.R. selbst in der Hand hat. Zentrales Element technischer Analysen sind für mich nach wie vor eigene Crawls der Kundenwebsites. So finde ich relativ schnell Probleme, mit denen auch Suchmaschinencrawler auf diesen Websites konfrontiert werden.
Bekannte Tools, denen jeder SEOler regelmäßig begegnet, sind Xenu’s Link Sleuth, Microsofts IIS SEO Toolkit oder der Screaming Frog – alle kostenfrei oder sehr günstig verfügbar und für den alltäglichen Gebrauch durchaus hilfreich. Dennoch haben alle drei ihre speziellen Anforderungen und natürlich ihre Grenzen. Gerade bei extrem umfangreichen Websites begeben wir uns hier regelmäßig an das Limit der Möglichkeiten. Ich war deshalb sehr froh, dass ich kürzlich die Gelegenheit bekam, ein noch recht junges Tool zu testen, dessen Entwickler sich zum Ziel gesetzt haben, genau diese Grenzen nicht zuzulassen: strucr.com.
Grundsätzlich ist strucr.com in vier Varianten verfügbar. Eine kostenfreie Schnupperversion taugt zum Kennenlernen und erlaubt das Analysieren kleiner privater Websites. Geht es um eine Erweiterung des Umfangs sind nach oben fast keine Grenzen gesetzt:
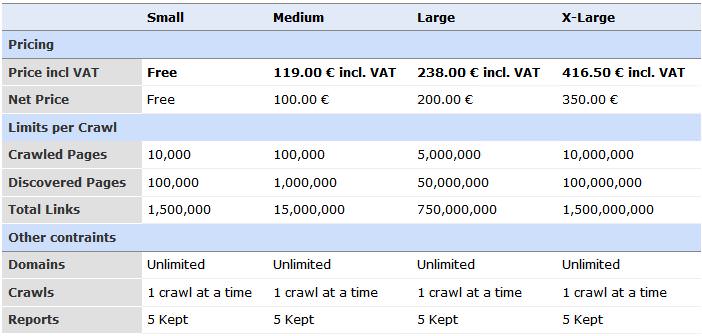
Dabei zielt strucr.com ganz klar auf den Einsatz im Enterprise-Bereich. Sämtliche Daten, die der Crawler erhebt, sind via API abrufbar und können so in eigene Tools und Auswertungen integriert und mit Daten aus anderen Anwendungen kombiniert werden. Ganz klar, dass die Entwickler von strucr.com deshalb enorme Anforderungen an die Qualität der Daten stellen. Bugs und Fehler dürfen hier einfach nicht passieren und müssen – sollten sie doch einmal auftreten – in kürzester Zeit behoben werden. Zur Qualitätssicherung muss der Crawler regelmäßige Tests gegen seine eigenen Bugs und natürlich seine Mitbewerber bestehen. Nach eigenen Aussagen, schaffen alternative Crawler gerade mal 65% dieser Tests.
Gleichzeitig liefert strucr.com den Großteil seiner Daten in absoluter Rohform und versucht Interpretationen weitestgehend zu vermeiden. Gegenüber einigen Wettbewerbern wirkt das zwar relativ plump und nicht so „hübsch“, hat aber den großen Vorteil, dass die Auswertung der Daten dem Kunden selbst überlassen bleibt, was gerade bei Verwendung der API sehr vorteilhaft ist. So können die gefunden Fehler im Kontext der Website selbst interpretiert werden. Es gibt einfach „Fehler“, die durchaus ihre Daseinsberechtigung haben. So kann beispielsweise eine große Anzahl an Seiten mit dem Meta-Tag robots=“noindex,nofollow“ für einen Shop typisch sein und sollte deshalb nicht zwangsläufig als negativ bewertet werden. Für ganz konkrete Fragestellungen oder zur Behebung komplexer Probleme sind die Entwickler hinter strucr.com übrigens auch gern bereit, weitere Features in ihren Crawler zu integrieren oder mit sehr speziellen Parametern zu crawlen.
Technisch steht hinter dem Tool eine solide IT-Infrastruktur, die bei dem Umfang der erhobenen Daten aber auch notwendig ist. Wer einmal versucht hat, die Website eines Onlineshops mit 200.000 Produkten und zahllosen Parametern (z.B. SessionIDs) mit einem der herkömmlichen Tools zu crawlen, wird – einen leistungsstarken PC vorausgesetzt – nach spätestens 12 Stunden verzweifelt sein. Im Agenturalltag passiert es mir in solchen Fällen nicht selten, dass zwischendurch entweder die IT des Kunden meine IP-Adresse blockiert oder mein Telefon klingelt und es Beschwerden hagelt. Im Gegensatz zu herkömmlichen Tools läuft strucr.com hingegen auf einem eigenen Server. Die Geschwindigkeit des Crawlvorgangs kann individuell abgestimmt werden. Um Einbrüche bei der Performance der gecrawlten Website zu vermeiden, kann und muss der Crawl daher mit der zuständigen IT-Abteilung abgestimmt werden.
Schauen wir uns aber mal die Auswertung, die strucr.com standardmäßig für einen Crawl liefert, beispielhaft anhand der Website eines relativ großen deutschen Reiseanbieters an. Die Basisfeatures verstehen sich fast von selbst und sind schnell erklärt:
- Anzeige beim Crawl gefundener Fehler mit konkreter Fehlerangabe, URL und Ladezeit
- Anzahl der gecrawlten Seiten, gefundenen Links und Ebenen, in denen die Seiten strukturell organisiert sind
- Anzahl der Seiten sortiert nach Typ (z.B. Nofollow, External) und http-Status (z.B. 301/302-Weiterleitungen, 404-Fehler)
- Gecrawlte Domains und Subdomains (intern und extern) mit Anzahl eingehender und ausgehender Links
- Anzahl eingehender und ausgehender Links pro gecrawlter Seite
Darüber hinaus erhebt strucr.com weitere Daten und Reports, die im Hinblick auf eine umfassende Websiteoptimierung extrem hilfreich sind:
Seiten nach Ladezeit
Während des Crawls werden die reinen HTML Response Times der Seiten gemessen und aufgezeichnet. So lassen sich schnell Probleme bei der Seitengröße identifizieren und damit die Seiten gezielt auf Geschwindigkeit optimieren.
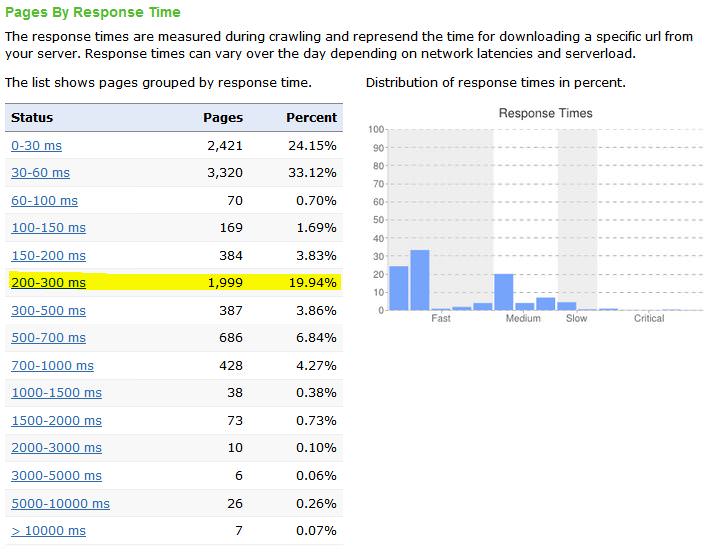
Mein Crawl zeigt mir beispielsweise auf den ersten Blick, dass meine Website bei den Ladezeiten zwar schon ein ganz gutes Bild abgibt, ich aber gerade im 200-300ms-Bereich noch einige Ausreißer habe, die ich mir einmal ansehen sollte. Ein Klick auf den Eintrag liefert detaillierte Informationen zu den Seiten, um die es sich dabei handelt. Offensichtlich sind dies Seiten, bei deren Bereitstellung im CMS viele verschiedene Informationen, wie z.B. Buchungszeitraum, Verfügbarkeit, Anzahl der Personen usw., berücksichtigt werden. Das sollte ich mir mal näher anschauen und eventuell die Zahl der Abfragen verringern. Hier ist es übrigens gut, dass strucr.com die Daten nicht interpretiert, denn ich weiß ebenso, dass es sich um Seiten handelt, die ich mit „noindex, nofollow“ markiert habe. Diese Aufgabe hat für mich aus SEO-Sicht deshalb keine hohe Priorität. Im Hinblick auf Usability und User Experience hingegen, sollte ich hier bei Gelegenheit trotzdem aktiv werden.
Seiten mit Anmerkungen
In dieser Übersicht liefert strucr.com eine Liste mit Anmerkungen zu meinen Seiten und die Zahl der Seiten, die zum jeweiligen Kriterium passen.

Die für mich aus SEO-Sicht besonders interessanten Hinweise habe ich gelb markiert. Hier sollte ich mir vor allem die Page Titles, Metadaten und Alt-Attribute anschauen, um meine Keywords besser einzusetzen und in den Suchergebnissen besser dazustehen. Gleichzeitig kann ich durch Auslagerung von CSS und Skripten sowie Größenangaben bei den Bildern bessere Ladezeiten bei meinen Seiten erreichen. Und nicht zuletzt sollte ich mir auch meine URL-Struktur einmal anschauen. Welche Fälle das genau betrifft, kann ich mir in diesem Report mit einem weiteren Klick auflisten lassen und zum Beispiel als Excel-Datei exportieren, die ich dann gezielt abarbeite. So brauche ich nur die Seiten anzufassen, die es wirklich betrifft.
Seiten und Content nach Level
Wie weit müssen Nutzer von der Startseite bis zu meinen wichtigsten Seiten bzw. meinem wichtigsten Content klicken? Diese Frage ist im Hinblick auf Usability und User Experience extrem wichtig, denn „verstecke“ ich meine wichtigsten Inhalte zu tief innerhalb meiner Websitestruktur, sind sie unter Umständen nicht auffindbar und bleiben deshalb unbeachtet.
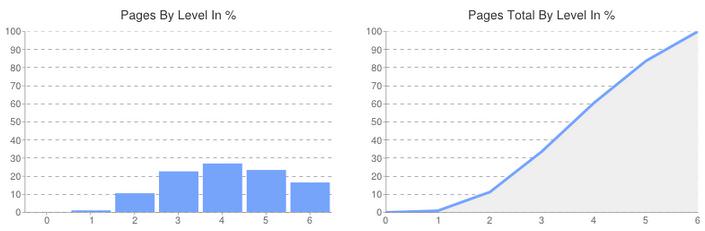
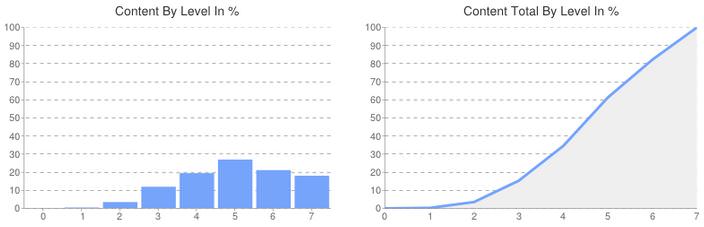
Hier gibt es bei meiner Website nichts zu bemängeln. Nutzer werden auf den ersten Ebenen nicht mit Inhalten erschlagen, finden aber bei weitergehender Recherche mit wenigen Klicks auch umfangreichere Informationen. Wäre es anders, fände ich hier sicher gute Ansatzpunkte zur Verbesserung der internen Verlinkung.
Seiten mit hohem 2D-Rank
Zur Berechnung der Stärke einer Seite verwendet strucr.com zwei relativ leicht zu erhebende Werte: den PageRank, der von strucr.com selbst auf Basis der eingehenden Links pro Seite berechnet wird, und den sog. CheiRank, der auf der Anzahl ausgehender Links basiert. Der von strucr.com berechnete PageRank hat mit dem von Google bekannten Wert allerdings wenig zu tun. Lediglich das zugrunde liegende mathematische Rechenmodell ist gleich, ansonsten ist der Wert hier glücklicherweise von Google unabhängig. Aus der Kombination von Page- und CheiRank bekommt man schließlich ein gutes Bild seiner stärksten und wertvollsten Seiten. Tauchen in dieser Liste vorrangig URLs auf, die keinen Wert für das Unternehmensziel bzw. Ziel der Website haben, sollte man an der internen Verlinkung arbeiten.
Abschließende Worte
Wie bereits erwähnt, sind alle von strucr.com erstellten Listen und erhobenen Daten per API verfügbar und können ebenso als CSV, TSV oder Excel-Datei heruntergeladen werden. So steht einer individuellen Weiterverarbeitung nichts im Wege. Gerade für Agenturen oder große Unternehmen ergeben sich damit viele Möglichkeiten. Gleichzeitig sind Freigaben aller Crawls und Accounts über bis zu vier verschiedene Nutzerrollen möglich. So sind beispielsweise jederzeit Freigaben für Kunden oder andere Abteilungen möglich, die sich gern selbst ein Bild von den Daten machen möchten.
Die Einsatzbereiche von strucr.com sind vielfältig. Im Agenturbereich sind eine einmalige Verwendung für eine konkrete Analyse, aber auch ein dauerhafter Einsatz für laufende, vor allem Technik-bezogene Optimierungen denkbar. Gerade Agenturen mit starkem technischem Fokus bekommen hier über den Crawler hinaus einen Partner, dem kein Problem zu komplex ist. Ebenso vorteilhaft ist aber auch der Einsatz von strucr.com im Unternehmensalltag. Von der IT- bis zur E-Commerce- oder SEO-Abteilung können hier alle profitieren. Warum nicht gleich strucr.com im Deploymentprozess einbinden um Änderungen an der Website vor dem Live-Gang direkt auf Herz und Nieren zu testen?
Über den Autor:
André Scharf ist Senior SEO Account Manager bei LBi und Betreiber eines eigenen Blogs.
Sehe mir strucr gerade genauer an. Wollte es schon seit einiger Zeit ausprobieren, aber erst dein Artikel hat mich dann wirklich dazu bewegt.
Bin überrascht, wie viel man allein schon kostenlos crawlen kann. Mir persönlich gefällt die „rohe“ Datenausgabe.
Finde es nur ein wenig Schade, dass beim 2D-Rank nicht angezeigt wird, wenn eine Seite noindex ist. Eine Hervorhebung wäre hier hilfreich.
Viele Grüße aus Innsbruck!
Stimmt. Allerdings sollte man sich Gedanken machen, wenn gerade eine Seite, die auf noindex steht, einen sehr hohen 2D-Rank hat. Das würde ja heißen, dass sie intern und extern sehr stark verlinkt ist, aber diese Stärke quasi nicht genutzt wird.
Eigentlich sollte man sich immer Gedanken machen, wenn eine Seite noindex ist. Jede noindex Seite bekommt Juice der nicht genutzt wird und kanibalisiert an der Crawlrate. Für die Seiten mit noindex gibt es ja einen Hint mit dem man all diese Seiten finden kann.
Naja, es gibt schon einige Arten von Seiten, bei denen noindex sehr wichtig sein kann. Das sind zum Beispiel oft Seiten hinter einem Login, die komplette Warenkorb- und Kaufabwicklung in einem Shop oder auch Artikel- oder Reiseseitem, die mit vielen komplexen Parametern und Filtern arbeiten.
@ Andre Scharf
Gebe ich dir recht! Es gibt einige Seiten bei denen NOINDEX von vorteil ist, vorallem auch beim Impressum oder bei Kontakt.
Diese Seiten sollten eig. nicht bei Google in der Suche auftauchen.
All die von dir beschriebenen Funktionen kann man wunderbar wunderbar maskieren und z.B. auf PRG-Pattern umstellen und dann kommt man ohne noindex aus und hält den Juice auf den verbleibenden Seiten. ;-)
Stimmt auch wieder. Wenn’s ja nur jemand machen würde. ;) Und wenn es dann doch mal einer macht, setzt er den Redirect zur selben Seite, sodass z.B. alle Seiten in einem Prozess mit derselben URL arbeiten. Das ist dann wieder für ein anständiges Tracking unpraktisch.