Unter den vielen Rankingfaktoren gibt es viele Faktoren die wichtig sind, aber auch welche, die weniger wichtig sind. Mit der Zeit kann es aber auch passieren dass bestimmte Faktoren an Wichtigkeit verlieren oder eben gewinnen. Beim PageSpeed war es so, denn er war lange Zeit ein ruhender Faktor, der kaum ernstgenommen wurde. Mit der Zeit hat er immer mehr an Bedeutung gewonnen und kann mittlerweile sogar für einen richtigen Rankingschub sorgen. Nicht umsonst stellt Google sogar das PageSpeed-Tool bereit und gibt sogar direkte Tipps, mit denen sich der PageSpeed verbessern lassen kann.
Strukturierte Daten – einfach erklärt
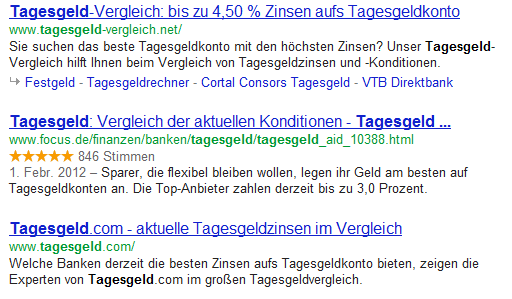
Heutzutage integriert Google verschiedenste Inhalte in die Ergebnislisten. Ohne prägnante Ergänzungen wie Videos, der Autorenverknüpfung und Bewertungssternen wird es immer schwieriger vom Suchenden in den Suchergebnislisten wahrgenommen und angeklickt zu werden. In einem Artikel von Search Engine Land wurde dieses Thema kürzlich aufgegriffen. In diesem Artikel zeigen wir die Vorteile strukturierter Daten, sowie die Verwendung … Weiterlesen …